입력 2025.07.08 15:38
| 수정 2025.07.08 16:18
- 건국대 김원준 교수팀, 컴퓨터 비전과 AI 분야 최고 권위 학술대회에서 발표

건국대학교 공과대학 김원준 교수(전기전자공학부) 연구팀이 개발한 ‘고성능 개방형 어휘 3차원 영상 분할 알고리즘’이 컴퓨터 비전 및 인공지능 분야 세계 최고 권위 학술대회 중 하나인 ICCV 2025(IEEE/CVF International Conference on Computer Vision, 국제 컴퓨터 비전학회(h5-index = 291))에서 발표된다.
연구팀은 텍스트 입력만으로 3차원 영상 내에서 사용자가 원하는 객체를 정밀하게 분할하고 편집할 수 있는 개방형 어휘(Open-vocabulary) 기반의 3차원 영상 분할 기술을 구현했다. 이 논문은 오는 10월 미국 하와이에서 열리는 ‘ICCV 2025’에서 소개될 예정이다.
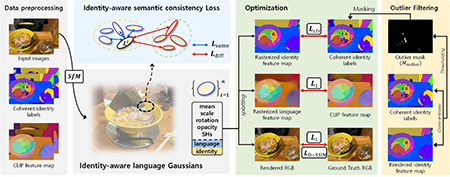
이번 연구는 서로 다른 시점에 존재하는 객체에 대한 언어 임베딩(Language Embedding)의 일관성을 유지하면서, 새로운 시점의 이미지를 생성할 수 있도록 언어 임베딩과 가우시안 스플래팅(Gaussian Splatting) 파라미터를 동시에 학습하는 전략을 새롭게 제안한 것이 핵심이다. 또한 대조적 학습(Contrastive Learning) 기법을 접목하여 새로운 시점 이미지 내 객체 검출 성능을 크게 향상시켰다.
이를 통해 정밀한 3차원 장면 렌더링은 물론, 생성된 이미지 상에서 텍스트 명령어를 기반으로 사용자 지정 객체 분할 및 편집이 가능해졌다. 해당 기술은 향후 3D 콘텐츠 생성, 3차원 장면 이해, 이머시브 서비스 분야 등에서 핵심적으로 활용될 수 있을 것으로 기대된다.
이번 논문의 제1저자는 건국대학교 장성민 석사과정생이며, 교신저자는 김원준 교수다. 본 연구는 과학기술정보통신부의 연구비 지원을 받아 수행됐다.
* 논문 제목: Identity-aware language Gaussian splatting for open-vocabulary 3D semantic segmentation
